
人工智能正从技术概念走向千行百业,实现多场景的实际落地,可以看到的是,人工智能热潮正推动AI芯片市场不断焕新。据Allied Market Research报告,全球机器学习芯片市场规模到2025年将达到约378亿美元。这不仅驱动着传统芯片公司战略和技术的转型,也推动了大量新玩家入局,在延续性或颠覆性创新方面频出奇招。
在不久前的英特尔On产业创新峰会(Intel Vision)上,英特尔就公布了在芯片、软件和服务方面取得的多项进展,展示了英特尔如何通过整合技术和生态系统,面向目前以及未来,为客户释放商业价值。其中专用于高性能深度学习AI训练的Gaudi处理器,能够让客户以较低成本进行更多训练。*新发布的Habana Gaudi2和Greco AI加速器是基于Synapse AI软件栈开发的,能够通过支持多样化架构,让终端用户充分利用处理器的高性能和高能效。
对于数据中心而言,由于数据集和人工智能业务的规模和复杂性日益增长,训练深度学习模型所需的时间和成本越来越高,根据IDC的数据,在2020年接受调查的机器学习从业者中,有74%的人对其模型进行过5-10次迭代训练,超过50%需要每周或更频繁地重建模型,26%的人则每天甚至每小时会重建模型。56%的受访者认为培训成本是阻碍其组织利用人工智能解决问题,创新和增强终端客户体验的首要因素。基于此,英特尔旗下的Habana Labs也在峰会当天发布了用于深度学习训练的第二代Gaudi处理器Gaudi 2,以及即将上市的用于深度学习推理的Goya处理器的后续产品Greco。它们采用了7纳米制程工艺,并以Habana的高能效架构为基础,面向数据中心的计算机视觉和自然语言应用,旨在为客户的模型训练和推理提供更高的性能。

基于与**代Gaudi相同的体系架构,Habana Gaudi 2处理器大幅提高了训练性能。客户在云端运行Amazon EC2 DL1实例以及本地运行Supermicro Gaudi训练服务器时,其性价比比现有GPU解决方案提升了40%,这些都来自于Gaudi2在架构上的进步:包括制程工艺从16纳米跃升至7纳米;在矩阵乘法(MME)和Tensor处理器核心计算引擎中引入了FP8在内的新数据类型;Tensor处理器的核心数量由8个增至24个;芯片上集成多媒体处理引擎,实现从主机子系统的卸载;片内封装的内存容量提升了3倍,从32GB提升到带宽2.45TB/秒的96GB HBM2E;两倍48MB的板载SRAM存储器以及基于RDMA (RoCE2) 的集成以太网从10个增至24个,在标准网络上实现高效的纵向和横向扩展。
近日Habana Gaudi 2深度学习处理器在MLPerf行业测试中的表现更是印证了这点,结果凸显了Gaudi2处理器在视觉(ResNet-50)和语言(BERT)模型上相比NVIDIA A100训练时间的优势。
对此,英特尔公司执行副总裁兼数据中心与人工智能事业部总经理 Sandra Rivera表示:“非常高兴能与大家分享Gaudi 2在MLPerf基准测试中的出色表现,我也为英特尔团队在产品发布仅一个月取得的成就感到自豪。我们相信,在视觉和语言模型中提供领先的性能能够为客户带来价值,有助于加速其AI深度学习解决方案。”
值得一提的是,本次MLPerf评测吸引了包括谷歌、NVIDIA、浪潮信息、百度、Intel-Habana、Graphcore等全球21家厂商和研究机构参与,共有264项评测成绩提交,是上一轮基准评测的1.5倍。评测任务涵盖了当下主流AI场景,包括自然语言处理(BERT)、智能推荐(DLRM)、图像分类(ResNet)、医学影像分割(3DU-Net)、轻量级目标物体检测(RetinaNet)、重量级目标物体检测(MaskR-CNN)、语音识别(RNN-T)以及强化学习(Minigo)8类AI任务。
借助Habana Labs的Gaudi平台,英特尔数据中心团队能够专注于深度学习处理器技术,让数据科学家和机器学习工程师得以高效地进行模型训练,并通过简单的代码实现新模型构建或现有模型迁移,提高工作效率的同时降低运营成本。
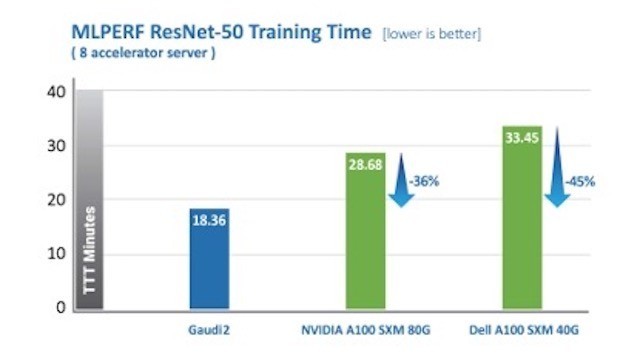
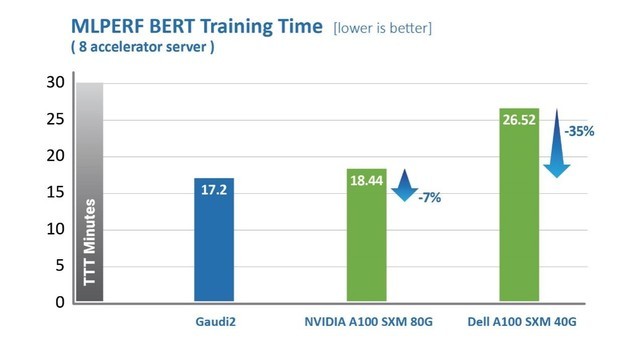
Habana Gaudi2处理器在缩短训练时间(TTT)方面相较**代Gaudi有了显著提升。Habana Labs于2022年5月提交的Gaudi2处理器在视觉和语言模型训练时间上已超越英伟达A100-80G的MLPerf测试结果。其中,针对视觉模型ResNet-50,Gaudi2处理器的TTT结果相较英伟达A100-80GB缩短了36%,相较戴尔提交的同样针对ResNet-50和BERT模型、采用8个加速器的A100-40GB服务器,Gaudi2的TTT测试结果则缩短了45%。
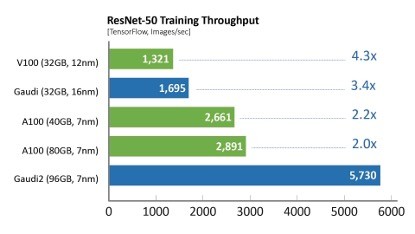
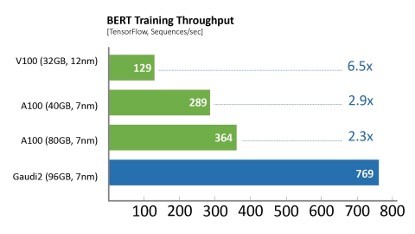
相比于**代Gaudi处理器,Gaudi2在ResNet-50模型的训练吞吐量提高了3倍,BERT模型的训练吞吐量提高了4.7倍。这些归因于制程工艺从16纳米提升至7纳米、Tensor处理器内核数量增加了三倍、增加GEMM引擎算力、封装的高带宽存储容量提升了三倍、SRAM带宽提升以及容量增加一倍。对于视觉处理模型的训练,Gaudi2处理器集成了媒体处理引擎,能够独立完成包括AI训练所需的数据增强和压缩图像的预处理。
两代Gaudi处理器的性能都是在没有特殊软件操作的情况下通过Habana客户开箱即用的商业软件栈实现的。
通过商用软件所提供的开箱即用性能,在Habana 8个GPU服务器与HLS-Gaudi2参考服务器上进行测试比对。其中,训练吞吐量来自于NGC和Habana公共库的TensorFlow docker,采用双方推荐的*佳性能参数在混合精度训练模式下进行测量。值得注意的是,吞吐量是影响*终训练时间收敛的关键因素。
除了Gaudi2在MLPerf测试中的卓越表现,**代Gaudi在128个加速器和256个加速器的ResNet基准测试中展现了强大的性能和令人印象深刻的近线性扩展,支持客户高效系统扩展。
Habana Labs首席运营官Eitan Medina表示:“我们*新的MLPerf测试结果证明Gaudi2在训练性能方面显著优势。我们将持续深度学习训练架构和软件创新,打造*具性价比的AI训练解决方案。”